Overview
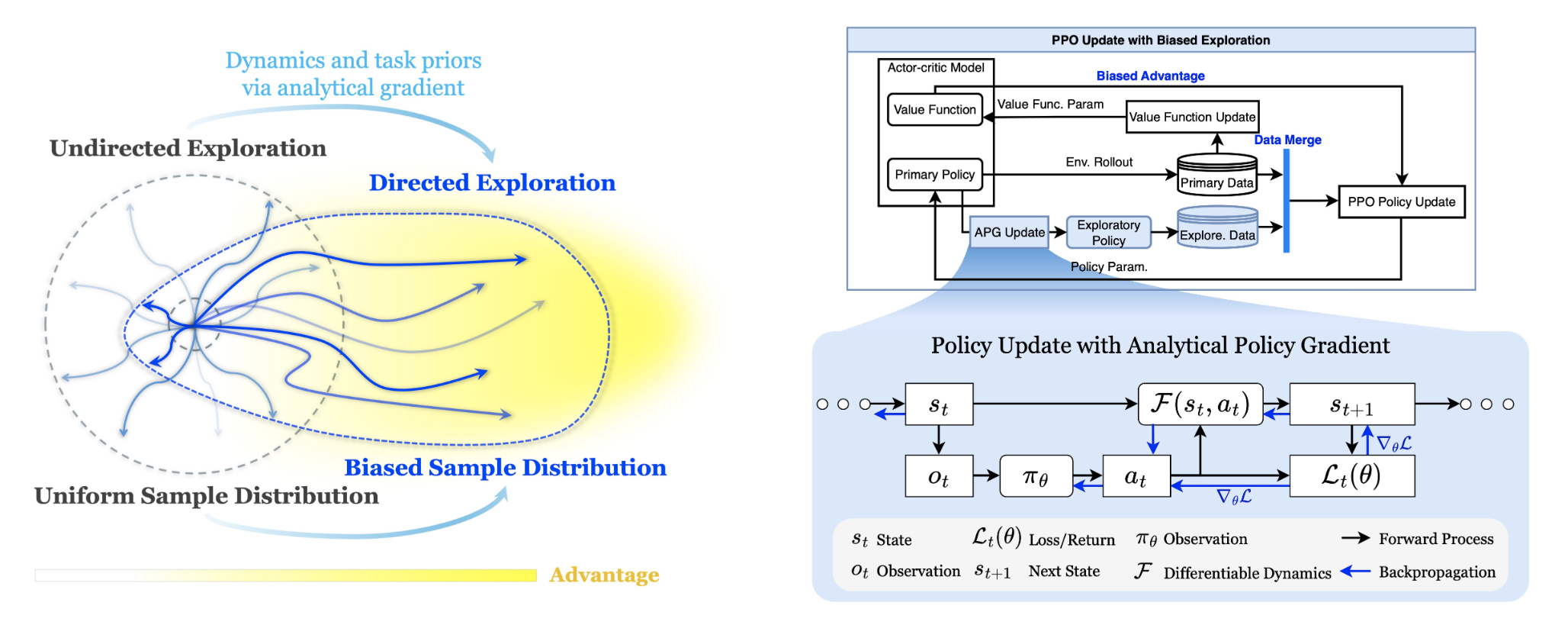
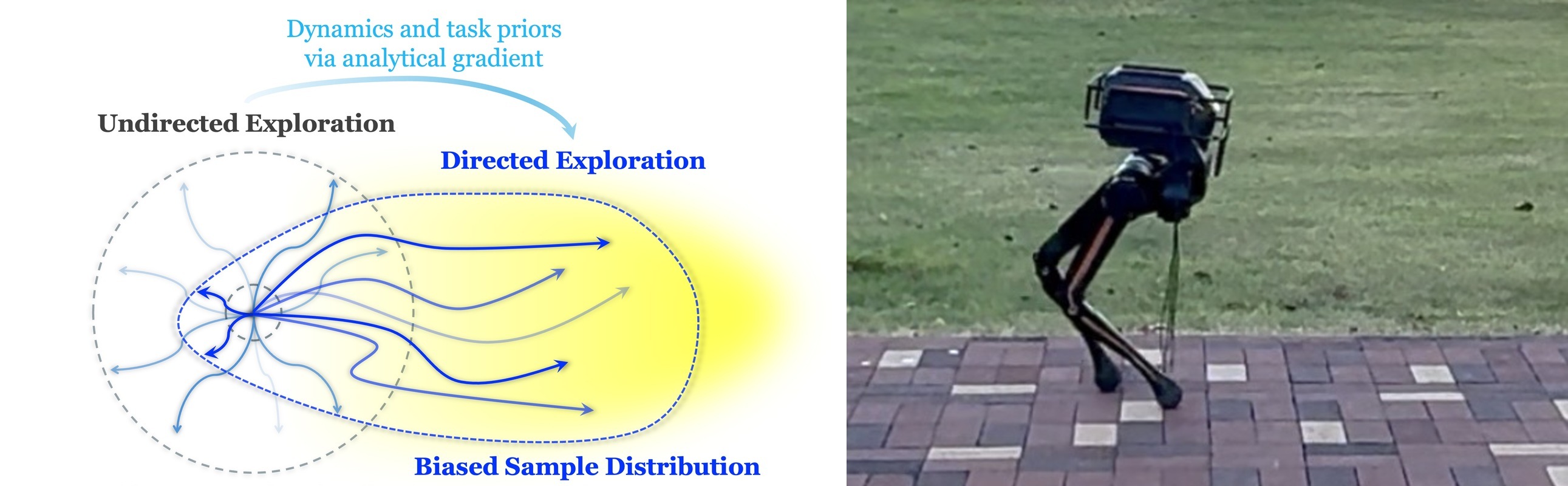
On-policy reinforcement learning (RL) algorithms have demonstrated great potential in robotic control, where effective exploration is crucial for efficient and high-quality policy learning. However, how to encourage the agent to explore the better trajectories efficiently remains a challenge. Most existing methods incentivize exploration by maximizing the policy entropy or encouraging novel state visiting regard- less of the potential state value. We propose a new form of directed exploration that uses analytical policy gradients from a differentiable dynamics model to inject task-aware, physics-guided guidance, thereby steering the agent towards high-reward regions for accelerated and more effective policy learning. We integrate our exploration approach into a widely used on-policy RL algorithm, Proximal Policy Optimization, to test and demonstrate its effectiveness. We conduct extensive benchmark experiments and demonstrate the effectiveness of the proposed exploration augmentation method. We further test our approach on a 6-DOF point-foot robot for velocity tracking locomotion, and conduct the simulation test and implement a successful sim-to-real deployment as the ultimate validation.
Algorithm Design